Was ist WDF*IDF?
WDF*IDF (Term Frequency-Inverse Document Frequency) ist ein statistisches Maß, das dazu verwendet wird, die Bedeutung von Begriffen in einem Dokument oder einer Sammlung von Dokumenten zu bestimmen. Es ist eine wichtige Technik für Information Retrieval und Suchmaschinenoptimierung, da es hilft, relevante Dokumente und Informationen zu identifizieren und zu ranken.
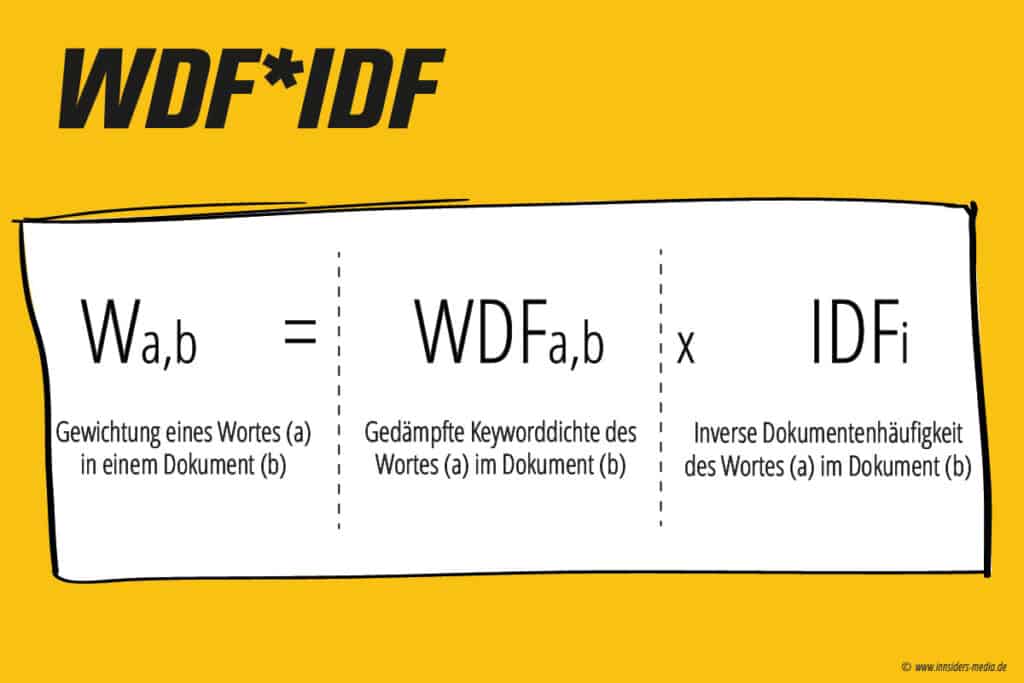
Berechnung des WDF*IDF
WDF*IDF berechnet sich aus zwei Faktoren: Term Frequency (TF) und Inverse Document Frequency (IDF). TF misst, wie oft ein bestimmter Begriff in einem Dokument vorkommt, während IDF die Häufigkeit des Begriffs in der Gesamtsammlung von Dokumenten misst. Ein häufiger Begriff in einem Dokument hat eine höhere TF, aber eine niedrigere IDF, während ein seltener Begriff in der Gesamtsammlung eine niedrigere TF aber eine höhere IDF hat.
Bewertung der Relevanz von Dokumenten
WDF*IDF ist ein wichtiger Faktor bei der Bewertung der Relevanz von Dokumenten für eine bestimmte Suche. Suchmaschinen wie Google nutzen es, um zu bestimmen, welche Dokumente am besten zu einer bestimmten Suchanfrage passen. Es hilft, irrelevantes Material zu filtern und die wichtigsten Informationen hervorzuheben.
Textklassifikation und Textextraktion
WDF*IDF kann auch für Textklassifikation und Textextraktion verwendet werden, um relevante Informationen aus großen Textsammlungen zu extrahieren. Es kann auch verwendet werden, um ähnliche Dokumente zu identifizieren, indem es ähnliche Begriffe und Themen betont.
In der Praxis werden bei der Berechnung von WDF*IDF normalerweise diverse Modifikationen vorgenommen, um die Gewichtung von Begriffen zu verbessern und zu berücksichtigen, dass bestimmte Begriffe in einigen Dokumenten oder Themen häufiger vorkommen als in anderen.
Fazit
Zusammenfassend lässt sich sagen, dass WDF*IDF ein wichtiger Ansatz für das Bewerten und Rangieren von Informationen ist und in den Bereichen des Informationsretrievals und der Suchmaschinenoptimierung eingesetzt wird. Es hilft, die Bedeutung von Begriffen in Dokumenten zu bestimmen und relevante Informationen hervorzuheben. Es berücksichtigt sowohl die Häufigkeit eines Begriffs in einem Dokument als auch seine Seltenheit in der Gesamtsammlung, was es zu einem wertvollen Werkzeug für die Bewertung der Relevanz von Dokumenten für eine bestimmte Suche macht. WDF*IDF kann auch für andere Zwecke wie Textklassifikation und Textextraktion genutzt werden.
Ähnliche Einträge